Overview
Welcome to the Cwtch Secure Development Handbook! The purpose of this handbook is to provide a guide to the various components of the Cwtch ecosystem, to document the known risks and mitigations, and to enable discussion about improvements and updates to Cwtch secure development processes.

What is Cwtch?
Cwtch (/kʊtʃ/ - a Welsh word roughly translating to “a hug that creates a safe place”) is a decentralized, privacy-preserving, multi-party messaging protocol that can be used to build metadata resistant applications.
- Decentralized and Open: There is no “Cwtch service” or “Cwtch network”. Participants in Cwtch can host their own safe spaces, or lend their infrastructure to others seeking a safe space. The Cwtch protocol is open, and anyone is free to build bots, services and user interfaces and integrate and interact with Cwtch.
- Privacy Preserving: All communication in Cwtch is end-to-end encrypted and takes place over Tor v3 onion services.
- Metadata Resistant: Cwtch has been designed such that no information is exchanged or available to anyone without their explicit consent, including on-the-wire messages and protocol metadata.
A Video Explainer
A (Brief) History of Metadata Resistant Chat
In recent years, public awareness of the need and benefits of end-to-end encrypted solutions has increased with applications like Signal, Whatsapp and Wire now providing users with secure communications.
However, these tools require various levels of metadata exposure to function, and much of this metadata can be used to gain details about how and why a person is using a tool to communicate. [rottermanner2015privacy].
One tool that did seek to reduce metadata is Ricochet first released in 2014. Ricochet used Tor v2 onion services to provide secure end-to-end encrypted communication, and to protect the metadata of communications.
There were no centralized servers that assist in routing Ricochet conversations. No one other than the parties involved in a conversation could know that such a conversation is taking place.
Ricochet wasn't without limitations; there was no multi-device support, nor is there a mechanism for supporting group communication or for a user to send messages while a contact is offline.
This made adoption of Ricochet a difficult proposition; with even those in environments that would be served best by metadata resistance unaware that it exists [ermoshina2017can] [renaud2014doesn].
Additionally, any solution to decentralized, metadata resistant communication faces fundamental problems when it comes to efficiency, privacy and group security (as defined by transcript consensus and consistency).
Modern alternatives to Ricochet include Briar, Zbay and Ricochet Refresh - each tool seeks to optimize for a different set of trade-offs e.g. Briar seeks to allow people to communicate even when underlying network infrastructure is down while providing resistant to metadata surveillance.
The Cwtch project began in 2017 as an extension protocol for Ricochet providing group conversations via untrusted servers, with an eye to enabling decentralized, metadata resistant applications (like shared lists and bulletin board)
An alpha version of Cwtch was was launched in February 2019, and since then the Cwtch team (run by the Open Privacy Research Society) has conducted research and development into cwtch and the underlying protocols and libraries and problem spaces.
Risk Model
Communications metadata is known to be exploited by various adversaries to undermine the security of systems, to track victims and to conduct large scale social network analysis to feed mass surveillance. Metadata resistant tools are in their infancy and research into the construction and user experience of such tools is lacking.
Cwtch was originally conceived as an extension of the metadata resistant protocol Ricochet to support asynchronous, multi-peer group communications through the use of discardable, untrusted, anonymous infrastructure.
Since then, Cwtch has evolved into a protocol in its own right, this section will outline the various known risks that Cwtch attempts to mitigate and will be heavily referenced throughout the rest of the document when discussing the various sub-components of the Cwtch Architecture.
Threat Model
It is important to identify and understand that metadata is ubiquitous in communication protocols, it is indeed necessary for such protocols to function efficiently and at scale. However, information that is useful to facilitating peers and servers is also highly relevant to adversaries wishing to exploit such information.
For our problem definition, we will assume that the content of a communication is encrypted in such a way that an adversary is practically unable to break (see tapir and cwtch for details on the encryption that we use, a and as such we will focus to the context to the communication metadata.
We seek to protect the following communication contexts:
- Who is involved in a communication? It may be possible to identify people or simply device or network identifiers. E.g., “this communication involves Alice, a journalist, and Bob a government employee.”.
- Where are the participants of the conversation? E.g., “during this communication Alice was in France and Bob was in Canada.”
- When did a conversation take place? The timing and length of communication can reveal a large amount about the nature of a call, e.g., “Bob a government employee, talked to Alice on the phone for an hour yesterday evening. This is the first time they have communicated.” *How was the conversation mediated? Whether a conversation took place over an encrypted or unencrypted email can provide useful intelligence. E.g., “Alice sent an encrypted email to Bob yesterday, whereas they usually only send plaintext emails to each other.”
- What is the conversation about? Even if the content of the communication is encrypted it is sometimes possible to derive a probable context of a conversation without knowing exactly what is said, e.g. “a person called a pizza store at dinner time” or “someone called a known suicide hotline number at 3am.”
Beyond individual conversations, we also seek to defend against context correlation attacks, whereby multiple conversations are analyzed to derive higher level information:
- Relationships: Discovering social relationships between a pair of entities by analyzing the frequency and length of their communications over a period of time. E.g. Carol and Eve call each other every single day for multiple hours at a time.
- Cliques: Discovering social relationships between a group of entities that all interact with each other. E.g. Alice, Bob and Eve all communicate with each other.
- Loosely Connected Cliques and Bridge Individuals: Discovering groups that communicate to each other through intermediaries by analyzing communication chains (e.g. everytime Alice talks to Bob she talks to Carol almost immediately after; Bob and Carol never communicate.)
- Pattern of Life: Discovering which communications are cyclical and predictable. E.g. Alice calls Eve every Monday evening for around an hour.
Active Attacks
Misrepresentation Attacks
Cwtch provides no global display name registry, and as such people using Cwtch are more vulnerable to attacks based around misrepresentation i.e. people pretending to be other people:
A basic flow of one of these attacks is as follows, although other flows also exist:
- Alice has a friend named Bob and another called Eve
- Eve finds out Alice has a friend named Bob
- Eve creates thousands of new accounts to find one that has a similar picture / public key to Bob (won't be identical but might fool someone for a few minutes)
- Eve calls this new account "Eve New Account" and adds Alice as a friend.
- Eve then changes her name on "Eve New Account" to "Bob"
- Alice sends messages intended for "Bob" to Eve's fake Bob account
Because misrepresentation attacks are inherently about trust and verification the only absolute way of preventing them is for users to absolutely validate the public key. This is obviously not-ideal and in many cases simply won't-happen.
As such we aim to provide some user-experience hints in the ui to guide people in making choices around whether to trust accounts and/or to distinguish accounts that may be attempting to represent themselves as other users.
A note on Physical Attacks
Cwtch does not consider attacks that require physical access (or equivalent) to the users machine as practically defendable. However, in the interests of good security engineering, throughout this document we will still refer to attacks or conditions that require such privilege and point out where any mitigations we have put in place will fail.
Cwtch Technical Basics
This page presents a brief technical overview of the Cwtch protocol.
A Cwtch Profile
Users can create one of more Cwtch Profiles. Each profile generates a random ed25519 keypair compatible with Tor.
In addition to the cryptographic material, a profile also contains a list of Contacts (other Cwtch profile public keys + associated data about that profile like nickname and (optionally) historical messages), a list of Groups (containing the group cryptographic material in addition to other associated data like the group nickname and historical messages).
2-party conversions: Peer to Peer
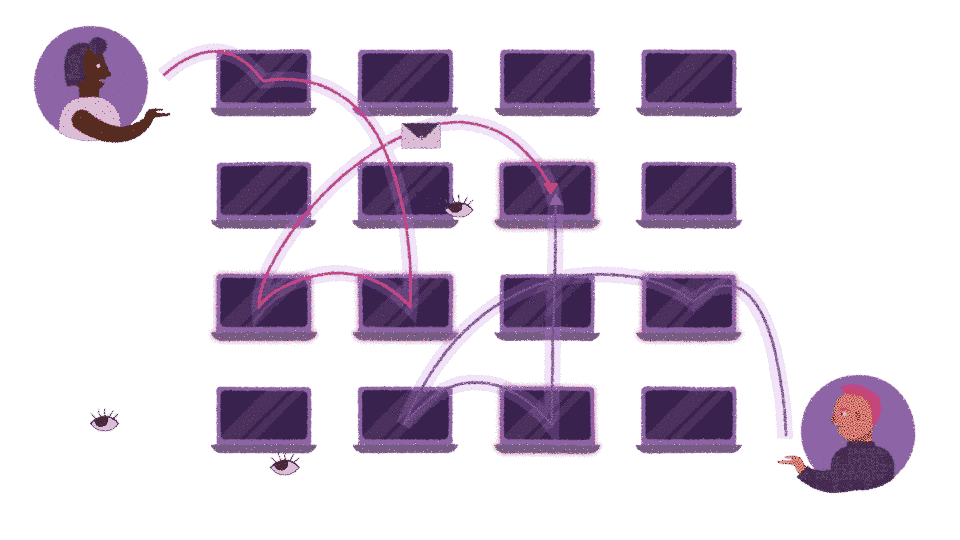
For 2 parties to engage in a peer-to-peer conversation both must be online, but only one needs to be reachable via their onion service. For the sake of clarity we often label one party the "inbound peer" (the one who hosts the onion service) and the other party the "outbound peer" (the one that connects to the onion service).
After connection both parties engage in an authentication protocol which:
- Asserts that each party has access to the private key associated with their public identity.
- Generates an ephemeral session key used to encrypt all further communication during the session.
This exchange (documented in further detail in authentication protocol) is offline deniable i.e. it is possible for any party to forge transcripts of this protocol exchange after the fact, and as such - after the fact - it is impossible to definitely prove that the exchange happened at all.
After, the authentication protocol the two parties may exchange messages with each other freely.
Multi-party conversations: Groups and Peer to Server Communication
Note: Metadata Resistant Group Communication is still an active research area and what is documented here will likely change in the future.
When a person wants to start a group conversation they first randomly generate a secret Group Key. All group communication will be encrypted using this key.
Along with the Group Key, the group creator also decides on a Cwtch Server to use as the host of the group.
For more information on how Servers authenticate themselves see key bundles.
A Group Identifier is generated using the group key and the group server and these three elements are packaged up
into an invite that can be sent to potential group members (e.g. over existing peer-to-peer connections).
To send a message to the group, a profile connects to the server hosting the group (see below), and encrypts
their message using the Group Key and generates a cryptographic signature over the Group Id, Group Server
and the decrypted message (see: wire formats for more information).
To receive message from the group, a profile connected to the server hosting the group and downloads all messages (since
their previous connection). Profiles then attempt to decrypt each message using the Group Key and if successful attempt
to verify the signature (see Cwtch Servers Cwtch Groups for an overview of attacks and mitigations).
Servers are Peers
In many respects communication with a server is identical to communication with a regular Cwtch peer, all the same steps above are taken however the server always acts as the inbound peer, and the outbound peer always uses newly generated ephemeral keypair as their "longterm identity".
As such peer-server conversations only differ in the kinds of messages that are sent between the two parties, with the server relaying all messages that it receives and also allowing any client to query for older messages.
Component Ecosystem Breakdown
Cwtch is made up of several smaller component libraries. This chapter will provide a brief overview of each component and how it relates to the wider Cwtch ecosystem.
openprivacy/connectivity
Summary: A library providing an ACN (Anonymous Communication Network ) networking abstraction.
The goal of connectivity is to abstract away the underlying libraries/software needed to communicate with a specific ACN. Right now we only support Tor and so the job of connectivity is to:
- Start and Stop the Tor Process
- Provide configuration to the Tor process
- Allow raw connections to endpoints via the Tor process (e.g. connect to onion services)
- Host endpoints via the Tor process (e.g. host onion services)
- Provide status updates about the underlying Tor process
For more information see connectivity
cwtch.im/tapir
Summary: Tapir is a small library for building p2p applications over anonymous communication systems.
The goal of tapir is to abstract away applications over a particular ACN. Tapir supports:
- Creating a cryptographic identity (including ephemeral identities)
- Maintaining a connection pool of inbound and outbound connections to services
- Handling various application-layers including cryptographic transcripts, authentication and authorization protocols, and token-based services via PrivacyPass,
For more information see tapir
cwtch.im/cwtch
Summary: Cwtch is the main library for implementing the cwtch protocol / system.
The goal of cwtch is to provide implementations for cwtch-specific applications e.g. message sending, groups, and file sharing(implemented as Tapir applications), provide interfaces for managing and storing Cwtch profiles, provide an event bus for subsystem splutting and building plugins with new functionality, in addition to managing other core functionality.
The cwtch library is also responsible for maintaining canonical model representations for wire formats and overlays.
cwtch.im/libcwtch-go
Summary: libcwtch-go provides C (including Android) bindings for Cwtch for use in UI implementations.
The goal of libcwtch-go is to bridge the gap between the backend cwtch library and any front end systems which may be written in a different language.
The API provided by libcwtch is much more restricted than the one provided by Cwtch directly, each libcwtch API typically packages up several calls to Cwtch.
libcwtch-go is also responsible for managing UI settings and experimental gating. It is also often used as a staging ground for experimental features and code that may eventually end up in Cwtch.
cwtch-ui
Summary: A flutter based UI for Cwtch.
Cwtch UI uses libcwtch-go to provide a complete UI for Cwtch, allowing people to create and manage profiles, add contacts and groups, message people, share files (coming soon) and more.
The UI is also responsible for managing localization and translations.
For more information see Cwtch UI
Auxiliary Components
Occasionally, Open Privacy will factor out parts of Cwtch into standalone libraries that are not Cwtch specific. These are briefly summarized here:
openprivacy/log
An Open Privacy specific logging framework that is used throughout Cwtch packages.
Message Formats
Peer to Peer Messages
PeerMessage {
ID string // A unique Message ID (primarily used for acknowledgments)
Context string // A unique context identifier i.e. im.cwtch.chat
Data []byte // The context-dependent serialized data packet.
}
Context Identifiers
-
im.cwtch.raw- Data contains a plain text chat message (see: overlays for more information) -
im.cwtch.acknowledgement- Data is empty and ID references a previously sent message -
im.cwtch.getValandim.cwtch.retVal- Used for requesting / returning specific information about a peer. Data contains a serializedpeerGetValstructure andpeerRetValrespectively.peerGetVal struct { Scope string Path string } type peerRetVal struct { Val string // Serialized path-dependent value Exists bool }
Plaintext / Decrypted Group Messages
type DecryptedGroupMessage struct {
Text string // plaintext of the message
Onion string // The cwtch address of the sender
Timestamp uint64 // A user specified timestamp
// NOTE: SignedGroupID is now a misnomer, the only way this is signed is indirectly via the signed encrypted group messages
// We now treat GroupID as binding to a server/key rather than an "owner" - additional validation logic (to e.g.
// respect particular group constitutions) can be built on top of group messages, but the underlying groups are
// now agnostic to those models.
SignedGroupID []byte
PreviousMessageSig []byte // A reference to a previous message
Padding []byte // random bytes of length = 1800 - len(Text)
}
DecryptedGroupMessage contains random padding to a fixed size that is equal to the length of all fixed length fields + 1800. This ensures that all encrypted group messages are equal length.
Encrypted Group Messages
// EncryptedGroupMessage provides an encapsulation of the encrypted group message stored on the server
type EncryptedGroupMessage struct {
Ciphertext []byte
Signature []byte // Sign(groupID + group.GroupServer + base64(decrypted group message)) using the senders cwtch key
}
Calculating the signature requires knowing the groupID of the message, the server the group is associated with and the decrypted group message (and thus, the Group Key). It is (ed25519) signed by the sender of the message, and can be verified using their public cwtch address key.
Groups
For the most part the Cwtch risk model for groups is split into two distinct profiles:
- Groups made up of mutually trusted participants where peers are assumed honest.
- Groups consisting of strangers where peers are assumed to be potentially malicious.
Most of the mitigations described in this section relate to the latter case, but naturally also impact the former. Even if assumed honest peers later turn malicious there are mechanisms that can detect such malice and prevent it from happening in the future.
Risk Overview: Key Derivation
In the ideal case we would use a protocol like OTR, the limitations preventing us from doing so right now are:
- Offline messages are not guaranteed to reach all peers, and as such any metadata relating to key material might get lost. We need a key derivation process which is robust to missing messages or incomplete broadcast.
Risk: Malicious Peer Leaks Group Key and/or Conversation
Status: Partially Mitigated (but impossible to mitigate fully)
Whether dealing with trusted smaller groups or partially-public larger groups there is always the possibility that a malicious actor will leak group messages.
We plan to make it easy for peers to fork groups to mitigate the same key being used to encrypt lots of sensitive information and provide some level of forward secrecy for past group conversations.
Risk: Active Attacks by Group Members
Status: Partially Mitigated
Group members, who have access to the key material of the group, can conspire with a server or other group members to break transcript consistency.
While we cannot directly prevent censorship given this kind of active collusion, we have a number of mechanisms in place that should reveal the presence of censorship to honest members of the group.
Mitigations:
- Because each message is signed by the peers public key, it should not be possible (within the cryptographic assumptions of the underlying cryptography) for one group member to imitate another.
- Each message contains a unique identifier derived from the contents and the previous message hash - making it impossible for collaborators to include messages from non-colluding members without revealing an implicit message chain (which if they were attempting to censor other messages would reveal such censorship)
Finally: We are actively working on adding non-repudiation to Cwtch servers such that they themselves are restricted in what they can censor efficiently.
Tapir
Designed to replace the old protobuf-based ricochet channels, Tapir provides a framework for building anonymous applications.
It is divided into a number of layers:
- Identity - An ed25519 keypair, required to establish a Tor v3 onion service and used to maintain a consistent cryptographic identity for a peer.
- Connections - The raw networking protocol that connects two peers. Connections are so far only defined over Tor v3 Onion Services (see: connectivity)
- Applications - The various logic that enables a particular information flow over a connection. Examples include shared cryptographic transcripts , authentication, spam guards and token based services. Applications provide Capabilities which can be referenced by other applications to determine if a given peer has the ability to use a given hosted application.
- Application Stacks - A mechanism for connecting more than one application together, e.g. authentication depends on a shared cryptographic transcript , and the main cwtch peer app is based on the authentication application.
Primitives
Identity
An ed25519 keypair, required to establish a Tor v3 onion service and used to maintain a consistent cryptographic identity for a peer.
- InitializeIdentity - from a known, persistent keypair: \(i,I\)
- InitializeEphemeralIdentity - from a random keypair: \(i_e, I_e\)
Applications
Transcript App
Dependencies: None
Initializes a Merlin-based cryptographic transcript that can be used as the basis of higher level commitment-based protocols
Transcript app will panic if an app ever tries to overwrite an existing transcript with a new one (enforcing the rule that a session is based on one, and only one, transcript.)
Authentication App
- Dependencies: Transcript App
- Capabilities Granted: AuthenticationCapability
- Capabilities Required: None
Engages in an ephemeral triple-diffie-hellman handshake to derive a unique, authenticated session key.
transcript.Commit()
The merlin transcript derived challenge is based on all the messages sent in the auth flow (and any that were sent prior to the Auth App)
// Derive a challenge from the transcript of the public parameters of this authentication protocol
transcript := ea.Transcript()
transcript.NewProtocol("auth-app")
transcript.AddToTranscript("outbound-hostname", []byte(outboundHostname))
transcript.AddToTranscript("inbound-hostname", []byte(inboundHostname))
transcript.AddToTranscript("outbound-challenge", outboundAuthMessage)
transcript.AddToTranscript("inbound-challenge", inboundAuthMessage)
challengeBytes := transcript.CommitToTranscript("3dh-auth-challenge")
Asymmetry
The client connection is guaranteed to possess the long term identity of the server connection through the properties of the underlying tor v3 onion connection.
As such if the server attempts to send a different long term identity to the client we can detect it and terminate the authentication protocol early.
Token App
Dependencies: Transcript App
- Capabilities Granted: HasTokensCapability
- Capabilities Required: None (implicitly guarded)
Allows the client to obtain signed, blinded tokens for use in another application.
While this application has no explicit requirement for any given capability,
we expect it to be protected via a preceeding app in an ApplicationChain e.g.
powTokenApp := new(applications.ApplicationChain).
ChainApplication(new(applications.ProofOfWorkApplication), applications.SuccessfulProofOfWorkCapability).
ChainApplication(tokenApplication, applications.HasTokensCapability)
Notes
- No direct testing (tested via integration tests and unit tests)
Known Risks
Impersonation of Peers
Status: Mitigated
By default, tor v3 onion services only provide one-way authentication, that is the client can verify a metadata resistant connection to the server but the server obtained no information about the client.
Tapir provides a peer-to-peer interface over this client-server structure through the Authentication application.
The Authentication application implements a 3-way, ephemeral diffie-hellman handshake to generate a shared session key. Once generated this session key is used to encrypt all traffic between the two peers for the duration of the session.
The session key is used to encrypt a challenge derived from the shared cryptographic transcript (based on merlin)
Only if all the above checks pass is the connection maintained open - otherwise the peer that detects a failure closes the connection.
Double Connections
Status: Mitigated
Because of the one-way authentication provided by Tor onion services there is a window between connection instantiation and the finalization of authentication when two valid connections can occur between the same two peers.
While these vestigial connections are not harmful, they do have the potential to confuse users and interfaces. To avoid ambiguity Tapir attempt to detect and close duplicate connections through a number of rules:
- If a connection open is attempted to a hostname that already has an open connection the connection attempt is aborted.
- After authentication the lookup happens again, and if another connection is found the newest connection is closed.
There is a small chance both peers will close their initiated connections if they also happen to start the connection attempt at exactly the sametime . This should be exceedingly rare in practice, and is further mitigated by an exponential backoff of connection retries by the ui
Finally, the Tapir interfaces WaitForCapabilityOrClose and GetConnection are
aware of the potential for duplicate connections and have logic that allows the
handling of such instances (such as returning an error when they are found
allowing a handling application to retry the request if a connection with a
given capability isn't returned)
Ephemeral Connections
Occasionally it is desirable to have a peer connect to a service without using their long term identity (e.g. in the case of connecting to a Cwtch Server).
In this case we want to enable a convenient way to allow connecting with an ephemeral identity.
It turns out that doing this securely requires maintaining a completely separate set of connections and applications in order to avoid side channels caused by duplicate connections handling.
As such the Cwtch Protocol Engine maintains two disctinct connection pools, one for avowed connections and another for ephemeral connections. All connections to known Cwtch Servers are made through the ephemeral pool.
Testing Status
Tapir features a number of well-defined integration tests which exercise not only the ideal case of two well-formed peers authenticating and messaging each other, but also a malicious peer attempting to bypass authentication.
In addition, unit tests are defined for a number of the specified applications (including Authentication) and many of the cryptographic primitives.
All tests are also run with the -race flag which will cause them to fail if
race conditions are detected. Both integration tests and unit tests are run
automatically for every pull request and main branch merge.
Packet Format
All tapir packets are fixed length (8192 bytes) with the first 2 bytes indicated the actual length of the message,
len bytes of data, and the rest zero padded:
| len (2 bytes) | data (len bytes) | paddding (8190-len bytes)|
Once encrypted, the entire 8192 byte data packet is encrypted using libsodium secretbox using the standard structure ( note in this case the actual usable size of the data packet is 8190-14 to accommodate the nonce included by secret box)
For information on how the secret key is derived see the authentication protocol
Authentication Protocol
Each peer, given an open connection \(C\):
\[ \ I = \mathrm{InitializeIdentity()} \\ I_e = \mathrm{InitializeEphemeralIdentity()} \\ \\ I,I_e \rightarrow C \\ P,P_e \leftarrow C \\ \\ k = \mathrm{KDF}({P_e}^{i} + {P}^{i_e} + {P_e}^{i_e}) \\ c = \mathrm{E}(k, transcript.Commit()) \\ c \rightarrow C \\ c_p \leftarrow C \\ \mathrm{D}(k, c_p) \stackrel{?}{=} transcript.LatestCommit() \\ \]
The above represents a sketch protocol, in reality there are a few implementation details worth pointing out:
Once derived from the key derivation function \(\mathrm{KDF}\) the key \(k\) is set on the connection, meaning the authentication app doesn't do the encryption or decryption explicitly.
The concatenation of parts of the 3DH exchange is strictly ordered:
- DH of the Long term identity of the outbound connection by the ephemeral key of the inbound connection.
- DH of the Long term identity of the inbound connection by the ephemeral key of the outbound connection.
- DH of the two ephemeral identities of the inbound and outbound connections.
This strict ordering ensures both sides of the connection derive the same session key.
Cryptographic Properties
During an online-session, all messages encrypted with the session key can be authenticated by the peers as having come from their peer (or at least, someone with possession of their peers secret key as it related to their onion address).
Once the session has ended, a transcript containing the long term and ephemeral public keys, a derived session key and all encrypted messages in the session cannot be proven to be authentic i.e. this protocol provides message & participant repudiation (offline deniable) in addition to message unlinkability (offline deniable) in the case where someone is satisfied that a single message in the transcript must have originated from a peer, there is no way of linking any other message to the session.
Intuition for the above: the only cryptographic material related to the transcript is the derived session key - if the session key is made public it can be used to forge new messages in the transcript - and as such, any standalone transcript is subject to forgery and thus cannot be used to cryptographically tie a peer to a conversation.
Connectivity
Cwtch makes use of Tor Onion Services (v3) for all inter-node communication.
We provide the openprivacy/connectivity package for managing the Tor daemon and setting up and tearing down onion services through Tor.
Known Risks
Private Key Exposure to the Tor Process
Status: Partially Mitigated (Requires Physical Access or Privilege Escalation to exploit)
We must pass the private key of any onion service we wish to set up to the
connectivity library, through the Listen interface (and thus to the Tor
process). This is one of the most critical areas that is outside of our
control. Any binding to a rouge tor process or binary will result in
compromise of the Onion private key.
Mitigations
Connectivity attempt to bind to the system-provided Tor process as the default, only when it has been provided with an authentication token.
Otherwise connectivity always attempts to deploy its own Tor process using a known good binary packaged with the system (outside of the scope of the connectivity package)
In the long term we hope an integrated library will become available and allow direct management through an in-process interface to prevent the private key from leaving the process boundary (or other alternative paths that allow us to maintain full control over the private key in-memory.)
Tor Process Management
Status: Partially Mitigated (Requires Physical Access or Privilege Escalation to exploit)
Many issues can arise from the management of a separate process, including the need to restart, exit and otherwise ensure appropriate management.
The ACN
interface provides Restart, Close and GetBootstrapStatus interfaces to
allow applications to manage the underlying Tor process. In addition the SetStatusCallback
method can be used to allow an application to be notified when the status of
the Tor process changes.
However, if sufficiently-privileged users wish they can interfere with this mechanism, and as such the Tor process is a more brittle component interaction than others.
Testing Status
Current connectivity has limited unit testing capabilities and none of these are run during pull requests or merges. There is no integration testing.
It is worth noting that connectivity is used by both Tapir and Cwtch in their integration tests (and so despite the lack of package level testing, it is exposed to system-wide test conditions)
Risks
Private information transiting the IPC boundary
Status: Requires privileged user to exploit
Information used to derive the encryption key used to save all sensitive data to the file system cross the boundary between the UI front-end and the App backend.
Intercepting this information requires a privileged position on the local machine.
Testing Status
Cwtch features one well-defined integration test which exercise the ideal case of three well-formed peers authenticating and messaging each other through an untrusted server.
Tests are run with the -race flag which will cause them to fail if
race conditions are detected.
Both integration tests and unit tests are run automatically for every pull request and main branch merge.
Resolved or Outdated Risks
Dependency on Outdated Protobuf Implementation
Status: Mitigated
The group features of Cwtch are enabled by an untrusted infrastructure protcol that was originally implemented using the older ricochet-based channels. The go code that was generated from these channels no longer works given the newest version of the protobufs framework.
We have removed protobufs entirely from the project by porting this functionality over the Tapir.
Proof of Work (PoW) Spam Prevention as a Metadata Vector
Status: Outdated: Cwtch now uses Token Based Services to separate challenges like PoW from resolving the tokens.
Processing capabilities are not constant, and so a malicious server could perform some correlations/fiddle with difficulty per connection in an attempt to identify connections over time.
Needs some statistical experimentation to quantify, but given the existing research detecting timeskews over Tor I wouldn't be surprised if this could be derived.
As for mitigation: Adding a random time skew might be an option,some defense against the server adjusting difficulty too often would also mitigate some of the more extreme vectors.
Additionally, Token Based Services and Peer-based Groups are both potential options for eliminating this attack vector entirely.
Thread Safety
Status: Mitigated
The Cwtch library evolved from a prototype that had weak checks around concurrency, and the addition of singleton behavior around saving profiles to files and protocol engines resulted in race conditions.
The inclusion of the Event Bus made handling such cases easier, and the
code is now tested via unit tests and integration test
running the -race flag.
Cwtch UI
The UI is now built using flutter.

Deanonymization through Content Injection
Status: Mitigated in several places
Unlike most UI frameworks, Flutter is not a de-facto HTML rendering engine. Any kind of malicious content injection is therefore not-elevated to a critical deanonymization risk in the default case.
To further mitigate this risk:
- Maintain our own set of core UI widgets that the rest of the app relies on that do not make use of any component widgets that may hit the network e.g. Image.network
- Mediate all Cwtch api networking calls through Tor
- Frequently test the UI for potential content injection vulnerabilities via FuzzBot
While none of these mitigations should be assumed robust by themselves, the combination of them should be sufficient to prevent such attacks.
Corruption of UI Chrome through Content Injection
Status: Mitigated
While we assess the mitigated-risk of content injection resulting in deanonymization vectors to be very low, the risk that malicious content causes UI chrome corruption requires additional consideration.
As a simple example, unicode control characters from conversations should not result in corruption to parts of the chrome that they are rendered with.
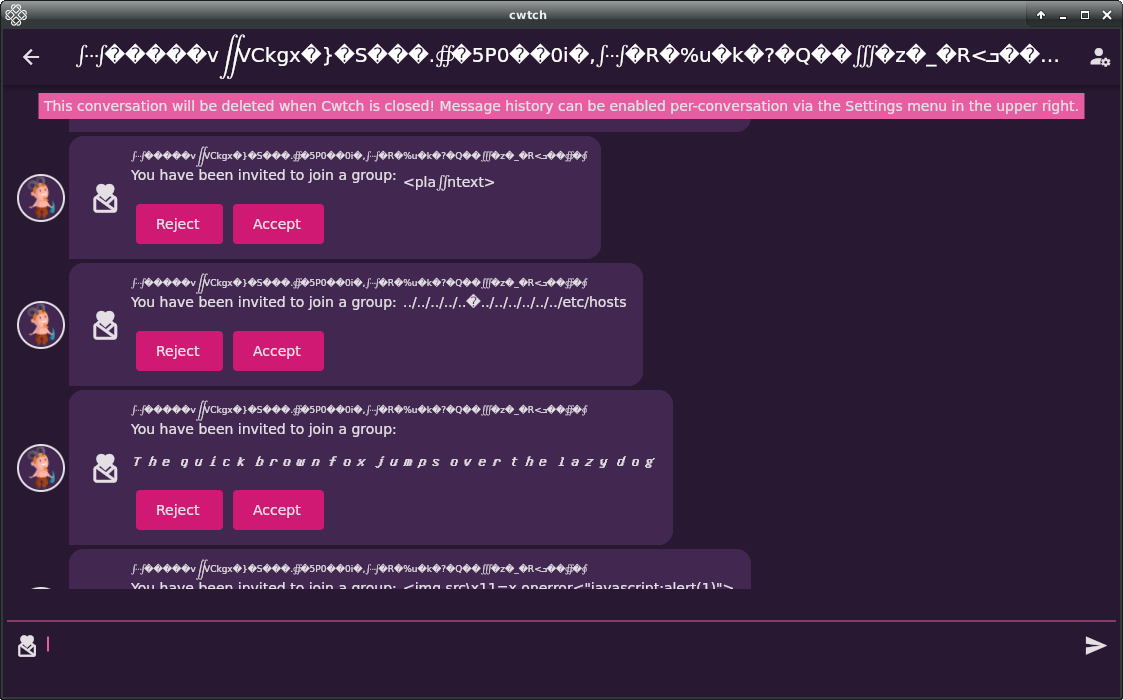
To mitigate this risk:
- All potentially malicious content is rendered separately at the widget level i.e. we do not mix trusted strings and untrusted strings in the same widget. This confined rendering differences tightly to just the malicious content.
- Frequently test the UI for potential content injection vulnerabilities via FuzzBot
Denial of Service through Spamming
Status: Partially Mitigated
There is currently no limitation on the number of messages that can be sent to a Cwtch server or by a Cwtch peer. Each message requires process and is added to the UI if valid.
We have put in work to ensure that an influx of messages does not degrade the app experience, however it will result in an increase in network bandwidth which may be intolerable or undesired for many people - especially those on metered connections (e.g. cellphone data plans)
In order to be suitable to deploy groups at a wide scale, the app requires a way to prevent Cwtch from fetching information over such connections, and this should likely be turned on by default.
Testing Status
The UI is subject to both manual testing, partially automated testing through fuzzbot, and fully automated testing during pull requests.
Profile Encryption & Storage
Profiles are stored locally on disk and encrypted using a key derived from user-known password (via pbkdf2).
Note that once encrypted and stored on disk, the only way to recover a profile is by rederiving the password - as such it isn't possible to provide a full list of profiles a user might have access to until they enter a password.
Unencrypted Profiles and the Default Password
To handle profiles that are "unencrypted" (i.e don't require a password to open) we currently create a profile with a defacto, hardcoded password.
This isn't ideal, we would much rather wish to rely on OS-provided key material such that the profile is bound to a specific device, but such features are currently patchwork - we also note by creating an unencrypted profile, people who use Cwtch are explicitly opting into the risk that someone with access to the file system may be able to decrypt their profile.
Related Code
https://git.openprivacy.ca/cwtch.im/cwtch/src/commit/3529e21b0e0763ca6ec20ddfd13e22c8070c4915/storage/v1/file_enc.go
Android Service
Adapted from: Discreet Log #11: Integrating FFI processes with Android services
In addition to needing to make plain ol’ method calls into the Cwtch library, we also need to be able to communicate with (and receive events from) long-running Cwtch goroutines that keep the Tor process running in the background, manage connection and conversation state for all your contacts, and handle a few other monitoring and upkeep tasks as well. This isn’t really a problem on traditionally multitasking desktop operating systems, but on mobile devices running Android we have to contend with shorter sessions, frequent unloads, and network and power restrictions that can vary over time. As Cwtch is intended to be metadata resistant and privacy-centric, we also want to provide notifications without using the Google push notification service.
The solution for long-running network apps like Cwtch is to put our FFI code into an Android Foreground Service. (And no, it’s not lost on me that the code for our backend is placed in something called a ForegroundService.) With a big of finagling, the WorkManager API allows us to create and manage various types of services including ForegroundServices. This turned out to be a great choice for us, as our gomobile FFI handler happened to already be written in Kotlin, and WorkManager allows us to specify a Kotlin coroutine to be invoked as the service.
If you’d like to follow along, our WorkManager specifications are created in the handleCwtch() method of MainActivity.kt, and the workers themselves are defined in FlwtchWorker.kt.
Our plain ol’ method calls to FFI routines are also upgraded to be made as WorkManager work requests, which allows us to conveniently pass the return values back via the result callback.
One initial call (aptly named Start) gets hijacked by FlwtchWorker to become our eventbus loop. Since FlwtchWorker is a coroutine, it’s easy for it to yield and resume as necessary while waiting for events to be generated. Cwtch’s goroutines can then emit events, which will be picked up by FlwtchWorker and dispatched appropriately.
FlwtchWorker’s eventbus loop is not just a boring forwarder. It needs to check for certain message types that affect the Android state; for example, new message events should typically display notifications that the user can click to go to the appropriate conversation window, even when the app isn’t running in the foreground. When the time does come to forward the event to the app, we use LocalBroadcastManager to get the notification to MainActivity.onIntent. From there, we in turn use Flutter MethodChannels to forward the event data from Kotlin into the frontend’s Flutter engine, where the event finally gets parsed by Dart code that updates the UI as necessary.
Messages and other permanent state are stored on disk by the service, so the frontend doesn’t need to be updated if the app isnt open. However, some things (like dates and unread messages) can then lead to desyncs between the front and back ends, so we check for this at app launch/resume to see if we need to reinitialize Cwtch and/or resync the UI state.
Finally, while implementing these services on Android we observed that WorkManager is very good at persisting old enqueued work, to the point that old workers were even being resumed after app reinstalls! Adding calls to pruneWork() helps mitigate this, as long as the app was shut down gracefully and old jobs were properly canceled. This frequently isn’t the case on Android, however, so as an additional mitigation we found it useful to tag the work with the native library directory name:
private fun getNativeLibDir(): String {
val ainfo = this.applicationContext.packageManager.getApplicationInfo(
"im.cwtch.flwtch", // Must be app name
PackageManager.GET_SHARED_LIBRARY_FILES)
return ainfo.nativeLibraryDir
}
…then, whenever the app is launched, we cancel any jobs that aren’t tagged with the correct current library directory. Since this directory name changes between app installs, this technique prevents us from accidentally resuming with an outdated service worker.
Message Overlays
Adapted from: Discreet Log #8: Notes on the Cwtch Chat API
Note: This section covers overlay protocols on-top of the Cwtch protcol. For information on the Cwtch Protocol messages themselves please see Message Formats
We envision Cwtch as a platform for providing an authenticated transport layer to higher-level applications. Developers are free to make their own choices about what application layer protocols to use, whether they want bespoke binary message formats or just want to throw an HTTP library on top and call it a day. Cwtch can generate new keypairs for you (which become onion addresses; no need for any DNS registrations!) and you can REST assured that any data your application receives from the (anonymous communication) network has been authenticated already.
For our current stack, messages are wrapped in a minimal JSON frame that adds some contextual information about the message type. And because serialised JSON objects are just dictionaries, we can easily add more metadata later on as needed.
Chat overlays, lists, and bulletins
The original Cwtch alpha demoed "overlays": different ways of interpreting the same data channel, depending on the structure of the atomic data itself. We included simple checklists and BBS/classified ads as overlays that could be viewed and shared with any Cwtch contact, be it a single peer or a group. The wire format looked like this:
{o:1,d:"hey there!"}
{o:2,d:"bread",l:"groceries"}
{o:3,d:"garage sale",p:"[parent message signature]"}
Overlay field o determined if it was a chat (1), list (2), or bulletin (3) message.
The data field d is overloaded, and lists/bulletins need additional information about what
group/post they belong to. (We use message signatures in place of IDs to avoid things like message
ordering problems and maliciously crafted IDs. This is also how the Cwtch protocol communicates to the
front end which message is being acked.)
Data structure
Implementing tree-structured data on top of a sequential message store comes with obvious performance disadvantages. For example, consider the message view, which loads most-recent-messages first and only goes back far enough to fetch enough messages to fill the current viewport, in comparison with a (somewhat pathological) forum where almost every message is a child of the very first message in the history, which could have been gigs and gigs of data-ago. If the UI only displays top-level posts until the user expands them, we have to parse the entire history before we get enough info to display anything at all.
Another problem is that multiplexing all these overlays into one data store creates "holes" in the data that confuse lazy-loaded listviews and scrollbars. The message count may indicate there is a ton more information to display if the user simply scrolls, but when it actually gets fetched and parsed we might realize that none of it is relevant to the current overlay.
None of these problems are insurmountable, but they demonstrate a flaw in our initial assumptions about the nature of collaborative message flows and how we should be handling that data.
Overlay Types
As stated above, overlays are specified in a very simple JSON format with the following structure:
type ChatMessage struct {
O int `json:"o"`
D string `json:"d"`
}
Where O stands for Overlay with the current supported overlays documented below:
1: data is a chat string
2: data is a list state/delta
3: data is a bulletin state/delta
100: contact suggestion; data is a peer onion address
101: contact suggestion; data is a group invite string
Chat Messages (Overlay 1)
The most simple over is a chat message which simply contains raw, unprocessed chat message information.
{o:1,d:"got milk?"}
Invitations (Overlays 100 and 101)
Instead of receiving the invite as an incoming contact request at the profile level, new inline invites are shared with a particular contact/group, where they can be viewed and/or accepted later, even if they were initially rejected (potentially by accident).
The wire format for these are equally simple:
{o:100,d:"u4ypg7yyyrrvf2aceeclq5dgwtkirzletltbqofnb6km7u542qqk4jyd"}
{o:101,d:"torv3eyJHcm91cElEIjoiOWY3MWExYmFhNDkzNTAzMzAyZDFmODRhMzI2ODY2OWUiLCJHcm91cE5hbWUiOiI5ZjcxYTFiYWE0OTM1MDMzMDJkMWY4NGEzMjY4NjY5ZSIsIlNpZ25lZEdyb3VwSUQiOiJyVGY0dlJKRkQ2LzFDZjFwb2JQR0xHYzdMNXBKTGJTelBLRnRvc3lvWkx6R2ZUd2Jld0phWllLUWR5SGNqcnlmdXVRcjk3ckJ2RE9od0NpYndKbCtCZz09IiwiVGltZXN0YW1wIjowLCJTaGFyZWRLZXkiOiJmZVVVQS9OaEM3bHNzSE9lSm5zdDVjNFRBYThvMVJVOStPall2UzI1WUpJPSIsIlNlcnZlckhvc3QiOiJ1cjMzZWRid3ZiZXZjbHM1dWU2anBrb3ViZHB0Z2tnbDViZWR6ZnlhdTJpYmY1Mjc2bHlwNHVpZCJ9"}
This represents a departure from our original "overlays" thinking to a more action-oriented representation. The chat "overlay" can communicate that someone did something, even if it's paraphrased down to "added an item to a list," and the lists and bulletins and other beautifully chaotic data can have their state precomputed and stored separately.
Lists / Bulletin Boards
Note: Expected to be Defined in Cwtch Beta 1.5
Image Previews
Built on the back of filesharing in Cwtch 1.3, image previews are keyed by the suggested filename’s extension (and no, we’re not interested in using MIME types or magic numbers) and advertised size. If enabled, the preview system will automatically download shared images to a configured downloads folder and display them as part of the message itself. (Due to limitations on Android, they’ll go to the app’s private storage cache, and give you the option to save them elsewhere later instead.) The file size limit is TBD but will obviously be much lower than the overall filesharing size limit, which is currently 10 gigabytes.
For now, we only support single-image messages, and any image editing/cropping will have to be done in a separate application. As we mention in the filesharing FAQ, image files also frequently contain significant hidden metadata, and you should only share them with people you trust.
KnownRisks
Other Applications and/or the OS Inferring Information from Images
Images must be stored somewhere, and for now we have chosen to store them unencrypted on the file system. We have done this for 2 reasons:
- In order to support more powerful file sharing schemes like rehosting we require the ability to efficiently scan files and deliver chunks - doing this through an encrypted database layer would harm performance.
- This information always has to transit the application boundary (either via display drivers, or storing and viewing the file in an external application) - there is nothing that Cwtch can do after that point in any case.
Malicious Images Crashing or otherwise Compromising Cwtch
Flutter uses Skia to render Images. While the underlying code is memory unsafe, it is extensively fuzzed as part of regular development.
We also conduct our own fuzz testing of Cwtch components. In that analysis we found a single crash bug related
to a malformed GIF file that caused the renderer to allocate a ridiculous amount of memory (and eventually be refused
by the kernel). To prevent this from impacting Cwtch we have adopted the policy of always enabling a maximum cacheWidth
and/or cacheHeight for Image widgets.
Malicious Images Rendering Differently on Different Platforms, Potentially Exposing Metadata
Recently a bug was found in Apple's png parser which would cause an image to render differently on Apple devices as it would on non-Apple devices.
We conducted a few tests on our Mac builds and could not replicate this issue for Flutter (because all Flutter builds use Skia for rendering), however we will continue to include such cases in our testing corpus.
For now image previews will remain experimental and opt-in.
Input
Risk: Interception of Cwtch content or metadata through an IME on Mobile Devices
Status: Partially Mitigated
Any component that has the potential to intercept data between a person, and the Cwtch app is a potential security risk.
One of the most likely interceptors is a 3rd party IME (Input Method Editor) commonly used by people to generate characters not natively supported by their device.
Even benign and stock IME apps may unintentionally leak information about the contents of a persons message e.g. through cloud synchronization, cloud translation or personal dictionaries.
Ultimately, this problem cannot be solved by Cwtch alone, and is a wider risk impacting the entire mobile ecosystem.
A similar risk exists on desktop through the use of similar input applications (in addition to software keyloggers), however we consider that fully outside the scope of Cwtch risk assessment (in line with other attacks on the security of the underlying operating system itself).
This is partially mitigated in Cwtch 1.2 through the use of enableIMEPersonalizedLearning: false. See
this PR for more information.
Cwtch Server
The goal of the Cwtch protocol is to enable group communication through Untrusted Infrastructure.
Unlike in relay-based schemes where the groups assign a leader, set of leaders, or a trusted third party server to ensure that every member of the group can send and receive messages in a timely manner (even if members are offline) - untrusted infrastructure has a goal of realizing those properties without the assumption of trust.
The original Cwtch paper defined a set of properties that Cwtch Servers were expected to provide:
- Cwtch Server may be used by multiple groups or just one.
- A Cwtch Server, without collaboration of a group member, should never learn the identity of participants within a group.
- A Cwtch Server should never learn the content of any communication.
- A Cwtch Server should never be able to distinguish messages as belonging to a particular group.
We note here that these properties are a superset of the design aims of Private Information Retrieval structures.
Malicious Servers
We expect the presence of malicious entities within the Cwtch ecosystem.
We also prioritize decentralization and permissionless entry into the ecosystem and as such we do not base any security claims on the following:
- Any non-collusion assumptions between a set of Cwtch servers
- Any third-party defined verification process
Peers themselves are encouraged to set up and run Cwtch servers where they can guarantee more efficient properties by relaxing trust and security assumptions - however, by default, we design the protocol to be secure without these assumptions - sacrificing efficiency where necessary.
Detectable Faults
- If a Cwtch server fails to relay a specific message to a subset of group members then there will be a detectable gap in the message tree of certain peers that can be discovered through peer-to-peer gossip.
- A Cwtch server cannot modify any message without the key material known to the group (any attempt to do so for a subset of group members will result in identical behavior to failing to relay a message).
- While a server can duplicate messages, these will have no impact on the group message tree (because of encryption, nonces and message identities) - the source of the duplication is not knowable to a peer.
Efficiency
As of writing, only 1 protocol is known for achieving the desired properties, naive PIR or "the server sends everything, and the peers sift through it".
This has an obvious impact on bandwidth efficiency, especially for peers using mobile devices, as such we are actively developing new protocols in which the privacy and efficiency guarantees can be traded-off in different ways.
As of writing, the servers allow both a complete download of all stored messages, and a request to download messages from a certain specified message.
All peers when they first join a group on a new server download all messages from the server, and from then on download only new messages.
Note: This behaviour does permit a mild form of metadata analysis. The server can new messages for each suspected unique profile, and then use these unique message signatures to track unique sessions over time ( via requests for new messages).
This is mitigated by 2 confounding factors:
- Profiles can refresh their connections at any time - resulting in fresh server session.
- Profiles can "resync" from a server at any time - resulting in a new call to download all messages. The most common usecase for this behaviour is to fetch older messages from a group.
In combination, these 2 mitigations place bounds on what the server is able to infer however we still cannot provide full metadata-resistance.
For potential future solutions to this problem see Niwl
Protecting the Server from Malicious Peers
The main risk to servers come in the form of spam generated by peers. In the prototype of Cwtch a spamguard mechanism was put in place that required peers to conduct some arbitrary proof of work given a server-specified parameter.
This is not a robust solution in the presence of a determined adversary with a significant amount of resources, and thus one of the main external risks to the Cwtch system becomes censorship-via-resource exhaustion.
We have outlined a potential solution to this in token based services but note that this also requires further development.
Key Bundles
Cwtch servers identify themselves through signed key bundles. These key bundles contain a list of keys necessary to make cwtch group communication secure and metadata resistant.
At the time of writing, key bundles are expected to contain 3 keys:
- A Tor v3 Onion Service Public Key for the Token Board (ed25519)- used to connect to the service over Tor to post and receive messages.
- A Tor v3 Onion Service Public Key for the Token Service (ed25519) - used to acquire tokens to post on the service via a small proof-of-work exercise.
- A Privacy Pass Public Key - used in the token acquisition process (a ristretto curve point) . See: OPTR2019-01
The key bundle is signed and can be verified via the first v3 onion service key, thus binding it to that particular oninon address.
Verifying Key Bundles
Profiles who import server key bundles verify them using the following trust-on-first-use (TOFU) algorithm:
- Verify the attached signature using the v3 onion address of the server. (If this fails, the import process is halted)
- Check that every key type exists. (If this fails, the import process is halted)
- If the profile has imported the server key bundle previously, assert that all the keys are the same. (If this fails, the import process is halted)
- Save the keys to the servers contact entry.
In the future this algorithm will likely be altered to allow the addition of new public keys (e.g. to allow tokens to be acquired via a Zcash address.)
Technically, at steps (2) and (3() the server can be assumed to be malicious, having signed a valid key bundle that does not conform to the specifications. When groups are moved from "experimental" to "stable" such an action will result in a warning being communicated to the profile.
Development
The main process to counter malicious actors in development of Cwtch is the openness of the process.
To enhance this openness, automated builds, testing and packaging are defined as part of the repositories - improving te robustness of the code base at every stage.

While individual tests aren't perfect, and all processes have gaps, we should be committed to make it as easy as possible to contribute to Cwtch while also building pipelines and processes that catch errors (unintential or malicious) as soon as possible.
Risk: Developer Directly Pushes Malicious Code
Status: Mitigated
trunk is currently locked and only 3 Open Privacy staff members have permission
to override it, in addition the responsibility of monitoring changes.
Further every new pull request and merge triggered automated builds & tests which trigger emails and audit logs.
The code is also open source and inspectable by anyone.
Risk: Code Regressions
Status: Partially Mitigated (See individual project entries in this handbook for more information)
Our automated pipelines have the ability to catch regressions when that behaviour is detectable.
The greatest challenge is in defining how such regressions are detected for the ui - where behaviour isn't as strictly defined as it is for the individual libraries.
Deployment
Risk: Binaries are replaced on the website with malicious ones
Status: Partially-mitigated
While this process is now mostly automated, should this automation ever be compromised then there is nothing in our current process that would detect this.
We need:
- Reproducible Builds - we currently use public docker containers for all builds which should allow anyone to compare distributed builds with ones built from source.
- Signed Releases - Open Privacy does not yet maintain a public record of staff public keys. This is likely a necessity for signing released builds and creating an audit chain backed by the organization. This process must be manual by definition.
Open Research Questions
The only way to build secure software is to attack it from every angle. There are a number of limitations and problems with Cwtch, both as designed and as implemented in our prototype. We are working on many of these, but would like to invite researchers to work with us on new solutions, as well as find new problems.
Here are the problems we know about:
The User Experience of Metadata Resistance Tools
Environments that offer metadata resistance are plagued with issues that impact usability, e.g. higher latencies than seen with centralized, metadata-driven systems, or dropped connections resulting from unstable anonymization networks. Additional research is needed to understand how users experience these kinds of failures, and how apps should handle and/or communicate them to users.
Scalability
Heavily utilized Cwtch servers increase message latency, and the resources a client requires to process messages. While Cwtch servers are designed to be cheap and easy to set up, and Cwtch peers are encouraged to move around, there is a clear balance to be found between increasing the anonymity set of a given Cwtch server (to prevent targeted disruptions) and the decentralization of Cwtch groups.
The (Online) First Contact Problem
Cwtch requires that any two peers are online at the same time before a key exchange/group setup is possible. One potential way to overcome this is through encoding an additional public key and a Cwtch server address into a Cwtch peer identifier. This would allow peers to send encrypted messages to an offline Cwtch peer via a known server, with the same guarantees as a Cwtch group message. This approach is not without issues, as by encoding metadata into the Cwtch identifier we allow adversaries to mount partially targeted attacks (in particular denial-of-service attacks against the Cwtch server with the aim of disrupting new connections). However, the benefit of first contact without an online key exchange is likely worth the potential DoS risk in many threat models.
Note: Something like niwl may now allow us to overcome this problem via fuzzy message detection and offline message retrieval.
Reliability
In Cwtch, servers have full control over the number of messages they store and for how long. This has an unfortunate impact on the reliability of group messages: if groups choose an unreliable server, they might find their messages have been dropped. While we provide a mechanism for detecting dropped/missing messages, we do not currently provide a way to recover from such failures. There are many possible strategies from asking peers to resend messages to moving to a different server, each one with benefits and drawbacks. A full evaluation of these approaches should be conducted to derive a practical solution.
Discoverability of Servers
Much of the strength of Cwtch rests on the assumption that peers and groups can change groups at any time, and that servers are untrusted and discardable. However, in this paper we have not introduced any mechanism for finding new servers to use to host groups. We believe that such an advertising mechanism could be built ver Cwtch itself.
References
-
Atwater, Erinn, and Sarah Jamie Lewis. "Token Based Services-Differences from Privacy Pass."
-
Brooks, John. Ricochet: Anonymous instant messaging for real privacy. https://ricochet.im. Accessed: 2018-03-10
-
Ermoshina K, Halpin H, Musiani F. Can johnny build a protocol? co-ordinating developer and user intentions for privacy-enhanced secure messaging protocols. In European Workshop on Usable Security 2017.
-
Ermoshina, K., Musiani, F. and Halpin, H., 2016, September. End-to-end encrypted messaging protocols: An overview. In International Conference on Internet Science (pp. 244-254). Springer, Cham.
-
Farb, M., Lin, Y.H., Kim, T.H.J., McCune, J. and Perrig, A., 2013, September. Safeslinger: easy-to-use and secure public-key exchange. In Proceedings of the 19th annual international conference on Mobile computing & networking (pp. 417-428).
-
Greschbach, B., Kreitz, G. and Buchegger, S., 2012, March. The devil is in the metadata—New privacy challenges in Decentralised Online Social Networks. In 2012 IEEE international conference on pervasive computing and communications workshops (pp. 333-339). IEEE.
-
Langley, Adam. Pond. https://github.com/agl/pond. Accessed: 2018-05-21.
-
Le Blond, S., Zhang, C., Legout, A., Ross, K. and Dabbous, W., 2011, November. I know where you are and what you are sharing: exploiting p2p communications to invade users' privacy. In Proceedings of the 2011 ACM SIGCOMM conference on Internet measurement conference (pp. 45-60).
-
Lewis, Sarah Jamie. "Cwtch: Privacy Preserving Infrastructure for Asynchronous, Decentralized, Multi-Party and Metadata Resistant Applications." (2018).
-
Kalysch, A., Bove, D. and Müller, T., 2018, November. How Android's UI Security is Undermined by Accessibility. In Proceedings of the 2nd Reversing and Offensive-oriented Trends Symposium (pp. 1-10).
-
Renaud, K., Volkamer, M. and Renkema-Padmos, A., 2014, July. Why doesn’t Jane protect her privacy?. In International Symposium on Privacy Enhancing Technologies Symposium (pp. 244-262). Springer, Cham.
-
Rottermanner, C., Kieseberg, P., Huber, M., Schmiedecker, M. and Schrittwieser, S., 2015, December. Privacy and data protection in smartphone messengers. In Proceedings of the 17th International Conference on Information Integration and Web-based Applications & Services (pp. 1-10).
-
Unger, Nik et al. “SoK: secure messaging”. In: Security and Privacy (SP ), 2015 IEEE Sympo-sium on. IEEE. 2015, pp. 232–249 link